Consequences: When using a monitor-actuator safety architecture, the monitor must be able to mitigate faults without requiring that the actuator software participates in that mitigation. The consequence of implementing a
monitor-actuator pair improperly is that when the actuator experiences a fault,
that fault may not be mitigated.
Accepted Practice:
- All monitor functions must execute on a separate microcontroller or other isolated hardware platform. This is to ensure that execution errors in the actuator cannot compromise the operation of the monitor.
- When a fault is detected, the monitor must mitigate the fault (e.g., do a system reset or close the throttle) regardless of any function performed (or not performed) by the actuator. This is to ensure that execution errors in the actuator cannot prevent fault mitigation from succeeding.
Discussion:
A
well established design technique for mitigating software errors is to have two
independent hardware components operate as a “monitor-actuator” CPU pair. The
actuator CPU is the component that actually performs the computation or control
function. For example, the actuator might compute a throttle angle command
based on accelerator position. (The name “actuator” is just a role that is
played – it can include calculation and other functions.) An independent monitor
Chip is used to avoid having the actuator CPU be a single point of failure. The
general assumption is that the actuator CPU may fail in some detectable way,
and the monitor’s job is to detect and mitigate any such failure. A common
mitigation technique is resetting the actuator CPU. (Note that for the
remainder of this section I use the term “actuator” for this design pattern to
mean an actuator CPU, and not a physical actuation output device.)

Monitor-Actuator Design Pattern. (Douglass 2002, Section 9.6)
The monitor must be implemented as an independent microcontroller that does an acceptance test (a computation to determine if the actuator’s outputs are safe) or other computation to ensure that the actuator is operating properly. The precise check on the actuator’s output used is application specific, and multiple such checks might be appropriate for a particular system. If the monitor detects that the actuator is not behaving in a safe manner, the monitor performs a fault mitigation function.
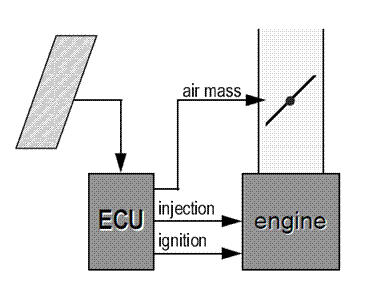
An example of such a monitor-actuator pair would be a throttle control microcontroller (the actuator) and an associated independent monitor microcontroller. If the throttle actuator CPU hangs or issues an unsafe throttle command, the monitor detects that condition and performs a fault mitigation action such as resetting the throttle actuator CPU. To perform this function, the monitor observes data being used by the actuator to perform computations as well as observes the outputs of the actuator. The monitor then decides if the throttle position is reasonable given the observed inputs (including, for example, brake pedal position) and resets the actuator when the checks fail. Examples of checks that would be expected in this sort of system would be a heartbeat check designed along the lines of a watchdog timer approach (ensuring the actuator is processing data periodically rather than being dead for some reason), and checking to ensure that commanded throttle position is reasonable given inputs to the actuator, such as the brake pedal position.
Proper operation of a monitor-actuator pair requires that the monitor has an ability to perform fault mitigation regardless of any execution problem that may be taking place in the actuator. For example, the monitor might use a hardware control line to reset the actuator and move the physical actuator to a safe position. Any assumption that the actuator will cooperate in fault mitigation (e.g., via a software task on the actuator accepting a reset request and initiating a reset), is considered a bad practice. Moreover, there should be no way for the actuator to inhibit the mitigation even if a software defect on the actuator actively tries to do so via faulty operation. The reason for this is that if the actuator is acting in a way that is defective, then relying on that defective component to perform any function properly (including self fault mitigation such as setting a trouble code or resetting) is a bad practice. Rather, the monitor must have a complete and independent ability to mitigate a fault in the actuator, regardless of the state of the actuator.
Selected Sources:
Douglass 2002 describes this pattern under in section 9.6. Douglass summarizes the operation as: “In the Monitor-Actuator Pattern, an independent sensor maintains a watch on the actuation channel looking for an indication that the system should be commanded into its fail-safe state.” The description emphasizes the need for independence of the two components.
“For the higher integrity levels, consider using an independent monitor processor to initiate a safe state.” (MISRA Software Guidelines 3.4.1.6.h, page 36). MISRA further makes it clear that the two “channels” (the monitor and the actuator) must “provide truly independent detection and reaction to errors” to provide safety mitigation (MISRA Report 2, p. 8, emphasis added).
Delphi’s automotive electronic throttle control system is said to use a primary processor and a redundant checking processor in keeping with this design practice, including an arrangement in which the second “processor performs redundant ETC sensor and switch reads.” (McKay 2000, pg. 8).
Safety standards also make it clear that the mere presence of a single point fault is unacceptable. For example, FAA DO-178b, the aviation software safety standard, specifically talks about a monitor/actuator pattern, saying that risk of failure is mitigated only if this condition (among several) is satisfied: “Independence of Function and Monitor: The monitor and protective mechanism are not rendered inoperative by the same failure condition that causes the hazard.” (DO 178-b Section 2.3.3.c).
References:
- Douglass, B. P., Real-Time Design Patterns: robust scalable architecture for real-time systems, Pearson Education, first printing, September 2002, copyright by Pearson in 2003.
- MISRA, Development Guidelines for Vehicle Based Software, November 1994 (PDF version 1.1, January 2001).
- MISRA, Report 2: Integrity, February 1995
- McKay, D., Nichols, G. & Schreurs, B., Delphi Electronic Throttle Control Systems for Model Year 2000; Driver Features, System Security, and EOM Benefits. SAE 2000-01-0556, 2000.
- Do-178b, Software considerations in airborne systems and equipment certification, Royal Technical Commission on Aviation, Dec 1, 1992.