(If you want to know more, see my
Webinar on CRCs and checksums based on work sponsored by the FAA.)
If you are looking for a lightweight error detection code, a CRC is usually your best bet. There are plenty of tutorials on CRCs and a web search will turn them up. If you're looking at this post probably you've found them already.
The tricky part is the "polynomial" or "feedback" term that determines how the bits are mixed in the shift-and-XOR process. If you are following a standard of some sort then you're stuck with whatever feedback term the standard requires. But many times embedded system designers don't need to follow a standard -- they just need a "good" polynomial. For a long time folk wisdom was to use the same polynomial other people were using on the presumption that it must be good. Unfortunately, that presumption is often wrong!
Some polynomials in widespread use are OK, but many are mediocre, some are terrible if used the wrong way, and some are just plain wrong due factors such as a typographical error.
Fortunately, after spending a many CPU-years of computer time doing searches, a handful of researchers have come up with optimal CRC polynomials. You can find my results below. They've been cross-checked against other known results and published in a reviewed academic paper. (This doesn't guarantee they are perfect! But they are probably right.)
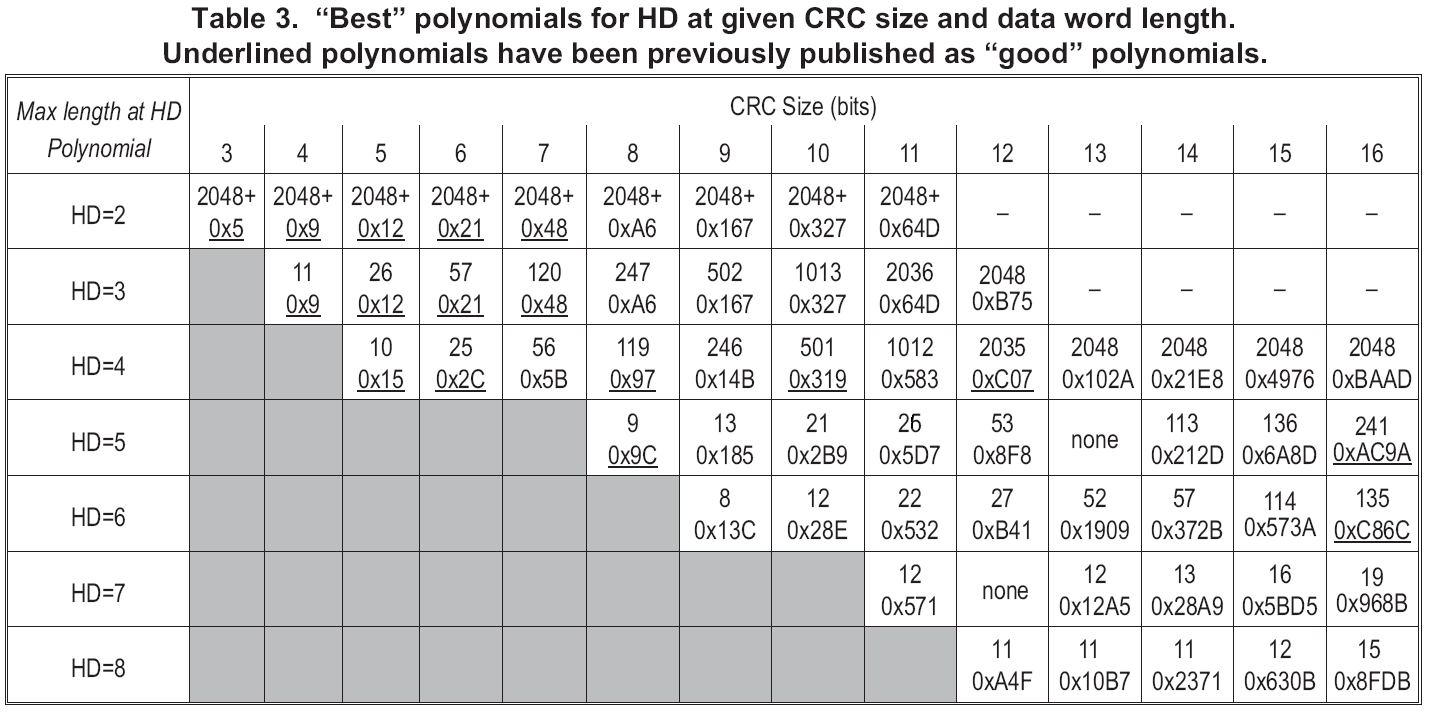
Here is as thumbnail description of using the table. HD is the Hamming Distance, which is minimum number of bit errors undetected. For example, HD=4 means all 1, 2, and 3 bit errors are detected, but some 4-bit errors are undetected, as are some errors with more than 4 bits corrupted.
The CRC Size is how big the CRC result value is. For a 14-bit CRC, you add 14 bits of error detection to your message or data packet.
The bottom number in each box within the table is the CRC polynomial in implicit "+1" hex format, meaning the trailing "+1" is omitted from the polynomial number. For example, hex 0x583 = binary 101 1000 0011 = x^11 + x^9 + x^8 + x^2 + x + 1. (This is "Koopman" notation in the
wikipedia page. No, I didn't write the wikipedia entry, and I wasn't trying to be gratuitously different. A lot of the comparison stuff happened after I'd already done too much work to have any hope of changing my notation without introducing mistakes.)
The top number in each box is the maximum data word length you can protect at that HD. For example, the polynomial 0x583 is an 11-bit CRC that can provide HD=4 protection for all data words up to 1012 bits in length. (1012+11 gives a 1023 bit long combined data word + CRC value.)
You can find the long version in this paper:
Koopman, P. & Chakravarty, T., "Cyclic Redundancy Code (CRC) Polynomial Selection For Embedded Networks,"
DSN04, June 2004. Table 4 lists many common polynomials, their factorizations, and their relative performance. It covers up to 16-bit CRCs. Longer CRCs are a more difficult search and the results aren't quite published yet.
You can find more discussion about CRCs and Checksums at my blog on that topic:
http://checksumcrc.blogspot.com/
(Note: updated 8/3/2014 to correct the entry for 0x5D7, which provides HD=5 up to 26 bits. The previous graphic incorrectly gave this value as 25 bits. Thanks to Berthold Gick for pointing out the error.)



{kind=link}