(If you want to know more, see my Webinar on CRCs and checksums based on work sponsored by the FAA.)
The tricky part is the "polynomial" or "feedback" term that determines how the bits are mixed in the shift-and-XOR process. If you are following a standard of some sort then you're stuck with whatever feedback term the standard requires. But many times embedded system designers don't need to follow a standard -- they just need a "good" polynomial. For a long time folk wisdom was to use the same polynomial other people were using on the presumption that it must be good. Unfortunately, that presumption is often wrong!
Some polynomials in widespread use are OK, but many are mediocre, some are terrible if used the wrong way, and some are just plain wrong due factors such as a typographical error.
Fortunately, after spending a many CPU-years of computer time doing searches, a handful of researchers have come up with optimal CRC polynomials. You can find my results below. They've been cross-checked against other known results and published in a reviewed academic paper. (This doesn't guarantee they are perfect! But they are probably right.)

(click for larger version)
(**** NOTE: this data is now a bit out of date. See this page for the latest ****)
(**** NOTE: this data is now a bit out of date. See this page for the latest ****)
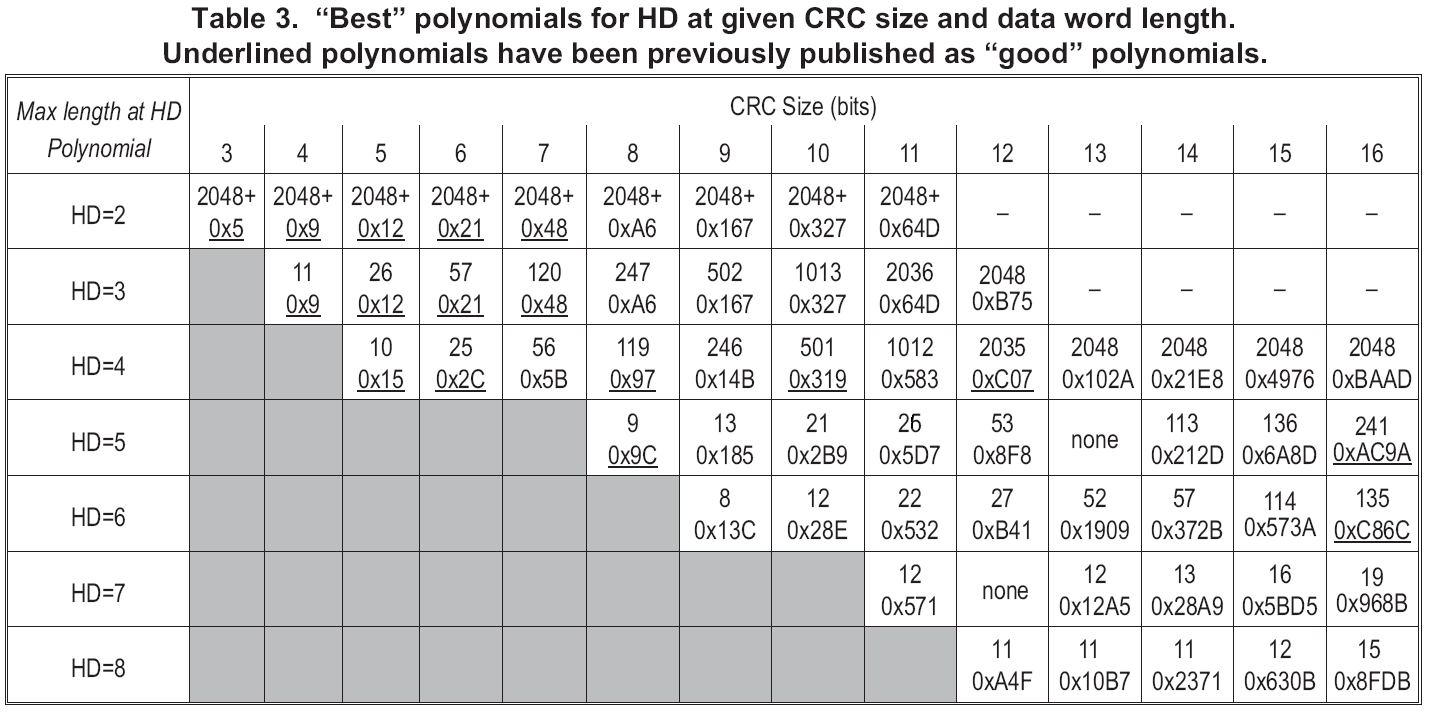
Here is as thumbnail description of using the table. HD is the Hamming Distance, which is minimum number of bit errors undetected. For example, HD=4 means all 1, 2, and 3 bit errors are detected, but some 4-bit errors are undetected, as are some errors with more than 4 bits corrupted.
The CRC Size is how big the CRC result value is. For a 14-bit CRC, you add 14 bits of error detection to your message or data packet.
The bottom number in each box within the table is the CRC polynomial in implicit "+1" hex format, meaning the trailing "+1" is omitted from the polynomial number. For example, hex 0x583 = binary 101 1000 0011 = x^11 + x^9 + x^8 + x^2 + x + 1. (This is "Koopman" notation in the wikipedia page. No, I didn't write the wikipedia entry, and I wasn't trying to be gratuitously different. A lot of the comparison stuff happened after I'd already done too much work to have any hope of changing my notation without introducing mistakes.)
The top number in each box is the maximum data word length you can protect at that HD. For example, the polynomial 0x583 is an 11-bit CRC that can provide HD=4 protection for all data words up to 1012 bits in length. (1012+11 gives a 1023 bit long combined data word + CRC value.)
You can find the long version in this paper: Koopman, P. & Chakravarty, T., "Cyclic Redundancy Code (CRC) Polynomial Selection For Embedded Networks," DSN04, June 2004. Table 4 lists many common polynomials, their factorizations, and their relative performance. It covers up to 16-bit CRCs. Longer CRCs are a more difficult search and the results aren't quite published yet.
You can find more discussion about CRCs and Checksums at my blog on that topic: http://checksumcrc.blogspot.com/
(Note: updated 8/3/2014 to correct the entry for 0x5D7, which provides HD=5 up to 26 bits. The previous graphic incorrectly gave this value as 25 bits. Thanks to Berthold Gick for pointing out the error.)


{kind=link}
Hi Phil,
ReplyDeleteHave you seen this paper?:
Fast Calculation of the Number of Minimum-Weight Words of CRC Codes by Peter Kazakov
http://netlab.cs.nchu.edu.tw/data/pdf/Fast%20calculation%20of%20the%20number%20of%20minimum-weight%20words%20of%20CRC%20codes.pdf
I have been looking for an optimal CRC16 polynomial for a 39byte/312bit message. I read this paper after reading your paper and was wondering if you knew how 0xBAAD would compare to 0xA801, the optimum value he lists for 310-325 bit messages? Do highly optimised values tend to deteriorate badly outside their optimal range? If my message length is likely to change in the future might I be better sticking to a more "general" optimal value that has good performance over a wider message length range?
Also if my message is 312 bits adding the CRC will make it 328 bits so do I choose a polynomial optimised for 312 bits or for 328 bits? (Given that the CRC is sent with the message it forms part of the message and is subject to the possibility of bit erros too.) 312 and 328 bits have different optimal polynomials according to Kazakov's paper.
Tony Smith
Hi Tony,
ReplyDeleteThanks for pointing out that paper, and indeed I have seen it. For those who want to dig deep into this topic you can see a list of my academic papers here, which reference that paper and many others.
I handle very specific questions about which polynomial to use in a particular situation on a consulting basis. (I get a lot of such questions and they take an hour to a day to answer thoroughly -- I just don't have enough evening hours to answer them all!) But to your general questions:
The recommended polynomials in my table have the maximum possible Hamming Distance at the stated lengths. Other optimal polynomials are a little better at shorter lengths, but usually not that much better. In all cases that I have looked at a polynomial that is optimal for shorter lengths at the same HD deteriorates badly (has reduced HD) as soon as you get to a longer length than the stated optimal length. So, if you might want to add a few bits to the data size someday, you'll want to stick with the ones I recommend. They were selected with exactly that scenario in mind.
If you have a 312 bit message (data word) that gives a 328 bit message+CRC (code word), you'll want to use the 312 bits for the table I give above. I don't remember which way Kazakov goes with that (there are a lot of papers I've read on this topic!), but most people specify "data word" length, and that is the tricky phrase you are looking for when reading a paper.
If you are glutten for data, you can see the point-wise optimal 16-bit polynomials for lengths up to 2048 bits at this link (go up a directory level to see what the columns mean). There are often several polynomials that are just as good at some lengths, so that data might not match Kazakov's results, but I did in fact at some point verify that my computed values were correct in light of Kazakov's paper.
I did not know that much about polynomial, until I read your information here. Thanks for giving me incite on this subject. KNOWLEDGE is power.
ReplyDelete"What's the best CRC polynomial to use?" This is a question that has been answered. Nice to see the graph presented it really gives you a good idea.
ReplyDeleteThis is a good article which features the benefits of CRC polynomial.
ReplyDelete"Some polynomials in widespread use are OK, but many are mediocre, some are terrible if used the wrong way, and some are just plain wrong due factors such as a typographical error."
ReplyDeleteThis is so true, as I've tried various polynomials before and my search for the best remains ceaseless. Thank you for posting a graph here, it really helped me understand the factors that constitute polynomials which matter greatly in my work. I can't afford to settle for one with lesser value.
Phil, Thanks for these great papers. I'm trying to follow along and would like to see if I have this right.
ReplyDeleteUsing CRC16-CCITT on a 16-bit data bus, I find the values 0x0a30 and 0x8832 that both result in a CRC of 0x808a when starting from the initial value 0xffff
0x0a30 and 0x8832 are different by three bits, so does that mean that CRC16-CCITT is HD=3 for a 16-bit bus? (3-bit difference was the worst-case I found after going through all combos)
So for a 16-bit CRC w/ a 16-bit dataword, there is probably a better polynomial that results in a high HD?
Lastly: for a given polynomial and CRC-width, as you decrease in data width does your HD always go down monotonically, or are there jumps?
thanks much for any clarifications you can give.
-m
Hi Max,
ReplyDeleteCRC 16-CCITT should have HD=4 at short lengths so I suspect there is something wrong with your example, but let me clarify based on your example. If the closest two values giving the same CRC differ by 3 bits, that is an undetected error and HD=3. It is also possible for HD=3 to have two bits flipped in the data and one bit in the CRC, or one bit in the data and two bits in the CRC. All three cases if undetected are HD=3. The initial value and data values don't actually matter. It is solely the position of the error bits that matters due to the linearity of CRCs. (Specifically, any combination of data bits and CRC bits that form a valid codeword also comprise an undetectable error.)
A 16-bit CRC with a 16-bit data word (32 total bits) can get HD=7 using polynomial 0x968B based on the table appearing in this blog.
For a particular CRC polynomial, HD usually decreases in big jumps. For example, 0x968B has HD=7 to 19 data bits, and HD=4 at 20 data bits. The jumps are often loosely related to the factorization of the polynomial, but there is no way to definitely predict the precise jumps without detailed evaluation except in a few special cases for low HD values.
Phil,
ReplyDeleteThanks for the HD explanation. I was correctly interpreting the paper and table, but I couldn't reproduce the results from the table which made me question whether I had read it right. I'll have to debug my code some more.
Sanity check here : Suppose I have a 16-bit bus and that I have N words coming in followed by a 16-bit CRC check. I'm continually updating the CRC every data word. 1 cycle = 16-bits. Is the "data-word width" considered N*16 or 16? I am assuming 16.
Assuming N is large, I was ignoring any errors in the CRC signature itself. My application is fault detection; the datapath is tested to have no hard faults and assumed to have no noise except a very very improbable SEU.
If I'm wrong and the data-width is the full length of a message (N*16) before I check the CRC signature, then I think I should be picking a regular smaller interval to do the check. This would enforce a smaller data-width and guarantee a higher HD, assuming a proven polynomial for that width is used.
-m
Max,
ReplyDeleteData word length is the total # of bits in a packet of information that is being protected. If you have 8 words of 16 bits it is 8*16=128 bits protected by a single CRC.
Also, CRCs are computed one bit at a time, not in word chunks unless you are using a lookup table approach. Errors in the CRC count in determining HD. From your description sounds like there may be some confusion with what you are doing compared to the standard approaches/assumptions, but hard to say what they are.
Due to very limited time I can't diagnose very specific problems, so I can't answer all questions or all parts of questions. I try to make time to respond to points I think will be of broad interest.
Best wishes,
-- Phil
Phil,
ReplyDeleteI appreciate your time spent answering these questions, it helps a lot. I'm trying to keep the questions as general as possible to appeal to a larger audience. My actual bus is wider than 16-bits but I figured I would work with CCITT for now just to reproduce findings.
Sorry for the implementation confusion: I'm implementing the CRC in circuit, so I'm updating the CRC a full word at a time every cycle with a tree of XORs. I'm trying to extrapolate the software-centric research to use in a better hardware implementation.
So my confusion lied in that I am updating the entire CRC register every cycle for N cycles until I check it.
From your above comment it sounds like I should consider my DW as N*Width when selecting an appropriate polynomial.
The parallel to software would be the table-based approaches where you are calculating a byte at a time independent of DW.
Thanks,
-m
Hi Phil,
ReplyDeleteThanks for the table, it's extremely helpful, I've noticed a pattern in the HD=3 and HD=4 rows which falls down for the higher HD rows.
For HD=4 and CRC=5 the protected data size is 10, going to CRC=6 the data size is 2*10 + (6-1) bits while going to HD=3 at CRC=5 the data size is 2*10 + (5+1) bits. This pattern holds right across your table.
Firstly, is this pattern true for all CRC sizes at HD=3 and HD=4 or is it just a coincidence? Secondly, why is the amount of data covered at HD=5 and higher so much lower than might be expected?
For HD=2,HD=3,HD=4 there are mathematical properties that guarantee some polynomials will achieve those HD values.
ReplyDeleteFor HD=2 and HD=3 a primitive polynomial does the trick. It will give HD=3 up to length of (2^k)-(k+1) bits. Note that the table shown only goes to 2048 bits. So a 12-bit polynomial of this form will give HD=3 up to (2^12)-(12+1)=4083 bits rather than the 2048 shown. This holds true for all size polynomials so long as they are primitive.
For HD=4 a primitive polynomial of order k-1 multiplied by (x+1) is what you want. In rough terms, the (x+1) term gives you parity, which picks up all one-bit and three-bit errors. The order k-1 primitive polynomial picks up all 2-bit errors, but since it is one bit shorter than k you get that up to (2^(k-1))-(k+1) bits. So for a 12 bit CRC that is (2^(12-1)-(12+1) = (2^11)-13 = 2035 bits. In *approximate* terms the best HD=4 polynomial is as effective for half the length as the best HD=3 polynomial. (Observant readers will notice there is an extra bit lost over what you might expect; it has something to do with the x+1 term but I don't have the derivations handy to explain it.) Again, this will hold for any CRC size so the 2048 terms are pessimistic in the table.
Beyond HD=4 the math special cases don't work. The interplay between the polynomials multiplied together is so complex that I've never seen anyone (including me) get math to explain it. (I've seen people try, but I've never seen the math be defect-free.) CRCs at that point are more or less pseudo-random number generators. They give you what they give you, and the results aren't so hot until you get to bigger CRCs.
There are bound lengths for higher HDs but they are non-intuitive and don't tell you which polynomials will be good -- they just tell you which ones might possibly be good. As a practical matter, brute-force search of many alternatives is the way to go for finding which polynomials are good ones.
Hi Phil!
ReplyDeleteI'm a newbee in CRC related stuff, I want to include MODBUS in a new desing, and I wanted to know, what is the relationship between the number of bits that I would detect in a data word and the number of bits that the poly generator has to have...
Many thanks in advance!
That's exactly what the table in this posting shows. But to answer the question you also need to know the length of the message you are trying to protect. Take a look at the original paper cited in the blog posting and it spells it out in a lot more detail.
ReplyDeleteI have this no-table byte-at-a-time CRC-CCITT routine, so my question is: Is there such a fast, no-table logic that can be performed for ANY such polynomial?
ReplyDelete/**************************************************************************/
/* Update CRC */
/* */
/* */
/* The generator is X^16 + X^12 + X^5 + 1 ( as defined by CCITT ) */
/* Very fast (40 cycles), if confusing, implementation found on the web */
/**************************************************************************/
void UpdateCrc(unsigned char data )
{
data ^= crc.byte.hi;
crc.byte.hi = crc.byte.lo;
crc.byte.lo = data;
crc.byte.lo ^= crc.byte.lo >> 4;
crc.byte.hi ^= crc.byte.lo << 4;
crc.word ^= (crc.byte.lo << 4) << 1;
}
There are approaches to no-table logic and small-table approaches that work depending on the number of 1 bits and the number of consecutive zero bits in the feedback polynomial. So it is faster for "sparse" polynomials of certain structures, but not worth doing for some other polynomials.
ReplyDeleteJustin Ray and I did a paper that addressed this topic and recommended polynomials that are particularly useful for providing good error detection combined with fast computation:
Ray, J., & Koopman, P. "Efficient High Hamming Distance CRCs for Embedded Applications," DSN06, June 2006.
http://www.ece.cmu.edu/~koopman/pubs/ray06_crcalgorithms.pdf
(Just to make sure, I'm not vouching for the accuracy of the above code, but it looks like a a typical no-table approach to that CRC polynomial.)
Thank you for responding! So I skimmed the paper, but must confess to being 'insufficient' in understanding enough details to implement what I specifically am looking for, which is (hopefully!) a 'no table' CRC16 X^16+X^15+X^2+X^1.
DeleteThank you for the nicely broken down explanations and also the published slides on http://de.slideshare.net/PhilipKoopman/crc-and-checksum-presentation-for-faa
ReplyDeleteI have some basic questions which I hope you could explain:
In your blog here you marked the table as outdated. Whats the difference to the new data? Are the polynomial not good enought or are the new ones just a bit better?
In the new table you removed the number of protected bits for HD=2. Whats the reason for this?
The new table has some slightly better polynomials. In some cases they are better because I have now been able to evaluated at longer lengths than the limit of the old table. And I think there was a slight typo in one of them. If you want to know the latest look here:
ReplyDeletehttp://users.ece.cmu.edu/~koopman/crc/
which is kept up to date as computations have a chance to run.
If you are using one of my previously published polynomials you can find exact performance data for that polynomial and many other published polynomials here:
http://users.ece.cmu.edu/~koopman/crc/hw_data.html
Additional reply on HD=2...
DeleteAll CRCs give HD=2 to infinite length. So the number of protected bits at HD=2 indicated that the old data only looked up to a certain length, and that the polynomial looked good for HD=2 up to that length. When considering longer lengths in some cases a different polynomial looks better (but the old data still gives HD=2 as indicated). The new tables consider HD=2 up to long enough lengths that the recommendations apply for any length, not just limited length datawords.
How do you calculate the hamming distance for a given generator polynomial given the length of the data and the number of CRC bits?
ReplyDeleteThere are several techniques. These results are based on an extremely optimized brute-force evaluation (try every combination of bit patterns and see which ones are undetected).
ReplyDeleteI have recently made available source code to do this. See this web page:
http://users.ece.cmu.edu/~koopman/crc/hdlen.html
(This code is primarily for verification and is a different code base than I used for actually doing the searches.)
Hi Phil,
ReplyDeleteThank you for all your detailed explanations regarding CRCs and your example source code to calculate HD, it's very useful.
I have a question that I hope you can help with.
In some of your slides you show the Probability of Undetected Error, based on a specific CRC, known BER and variable Data Word size.
I am not mathematically minded and am struggling with the calculation to determine Pud to generate a graph of Data Word length vs Pud (e.g. the graphs on page C-17 of your FAA report "Selection of Cyclic Redundancy Code and Checksum Algorithms to Ensure Critical Data Integrity").
I have been using the values from your HD tables and a known BER but cannot generate the correct Pud value, so my method of calculation is clearly not correct.
The reason I ask is that I have to calculate Pud for a serial link with (varying) Data Word length up to 16kbits, with BER = 10^-5 up to 10^8, ensuring that Pud is better than 10^-16 for all Data Words.
Is there a simple calculation to determine Pud given a BER, Data Word Length, number of undetected errors for that length (from your HD tables) and HD (again, from your tables) for that CRC/length combination?
Thanks again for all the information, it's been a huge help!
I can't offer help on a specific project on this blog, but can provide general comments that might be useful to all readers.
ReplyDeleteAn example of how to work through evaluating error detection effectiveness can be seen at the first slide show here:
http://checksumcrc.blogspot.com/2014/09/aviation-crc-checksum-practices.html
(CRC presentation 25 Sept. 2014) starting at slide 70. This is an example evaluation method created by my Honeywell collaborators (Kevin & Brendon).
In general you'll probably find that the limiting cases is the highest BER on the longest word (longer words are bigger targets to hit => tend to have more bit errors => will have highest probability of exceeding the HD)
That's great Phil, the descriptions in the slides have cleared up some queries I had on the calculations.
ReplyDeleteAnd thank you for your comments, it's all very much appreciated!
Hi Phil,
ReplyDeleteI hope you will be able to help me with a query I have on CRCs? I am implementing a serial link, and the data is being secured with a standard 32-bit CRC before being sent. However, due to bandwidth restrictions, I might transmit only the LS 16-bits of the CRC within the serial message. If I do this, would the effectiveness of the checking provided by the LS 16-bits of the CRC be of any use? If not, would I be better to use a strong 16-bit CRC to calculate and send in the serial message?
Thanks again for providing CRC information on this website, it's by far the best resource available!
If you truncate any 32-bit CRC you are going to lose the HD properties and end up with HD=1. So you are always better off using a good 16-bit CRC compared to a truncated 32-bit CRC (and this goes for all sizes). The truncated CRC will still in general provide protection in terms of being a pseudo-random number, but HD properties are lost.
DeleteHi Phil,
DeleteThanks for your fast response and for the clear information, it's a big help!
Dear Phil,
ReplyDeleteI have a question concerning CRC polynomial selection and the Integrity Level to be achieved for the data. For example in automotive, are there some guidelines regarding CRC polynomial selection to be compliant is an ASILD constraints on the data integrity. Maybe my question has no sense, sorry;-).
Thanks
Embedded safety critical networks typically pick a CRC polynomial with HD=6. There's a bit more to getting it right, however. See my FAA report blog post.
ReplyDeletehttps://betterembsw.blogspot.com/2015/04/faa-crc-and-checksum-report.html
If I have a short message, say 32 characters from a limited set of ascii characters (10 characters "0"-"9"), further more, I am using the crc32 algorithm familiar to PHP and Python (and others?), then is that CRC very useful for "correcting" introduced errors? How many errors can it correct. There is a lot of information about "detecting" corruption, but CRC should allow some amount of correction, right?
ReplyDeleteIn principle CRCs can be used for error correction if you pick one with a big enough Hamming Distance (each corrected bit consumes 2 bits of HD). But you'd probably have to use trial and error to figure out which bit was incorrect as far as I know. The exact method is not something I have a writeup for at this time.
ReplyDeleteHi Phil!
ReplyDeleteIf I send a message and at the last moment decide to corrupt its CRC. So I expect it to be discarded on receive. But how to do it (corrupt CRC) in the right way? If I choose arbitrary wrong value for CRC and message get some error bits during transmission this value can turn into rigth CRC. How to be sure that corrupted CRC value gives the same level of protection against errors in the message as rigth one?
This is more complicated than I can answer as an anonymous comment. You might try flipping HD/2 bits and that should give you HD/2 protection, but I haven't done any significant analysis.
ReplyDeleteHi Phil,
ReplyDeleteIs it possible to evaluate which is better: a series of shorter data+CRC or single larger data block with larger CRC? Say, we have:
[ Data100 + CRC8(0x83) + Data100 + CRC8(0x83) ] vs [ Data200 + CRC16(0xac9a) ]
Which is better if we evaluate a general averaged ability to detect 1-8 (1-n) bit errors instead of minimum detectable error bits? I understand that left side gives HD4 + HD4 = HD4 in the worst case, but I'm also interested in *average* characteristics (error detection probability), because I believe that real applications is not only about the worst case.
If small multiple blocks give worse general detection probability, is that a large difference?
What if we escalate it to: CRC8 * 4 vs CRC32?
If we have (HD=4) * 4 vs HD = 8, maybe the left side would work better if we have independent BER?
Thanks,
Audrius
Audrius,
DeleteFrom everything I've seen you are always better off with one large CRC compared to multiple smaller CRCs because you can get higher HD. But another reason is you get better mixing of bits and in general better mixing gives better performance. In the limit an XOR checksum is 32 x 1 bit "CRCs" and is not only bad HD but also bad error detection. Addition checksums only mix adjacent bits, etc.
CRCs are a convolution-style operation that mix all the bits, so are likely to give best error detection even for higher number of bit errors and longer burst errors.
DeleteHi Phil!
ReplyDeleteI had a look into your hdlen computation code. It works fine, alas I am not able to grasp how it works. Is there some text that explains how it works more detailed than the code comments?
Also the algorithm (or at least your C implementation) is suited for CPUs only. Did you ever consider (or did you actually try) to implement an algorithm for, lets say GPUs or FPGAs to speed up the search? Or do you know someone who did?
The short version is that hdlen walks bits across the data word (1 bit, 2 bits, ...) and counts bits in the resultant CRC value looking for a small enough number to violate the current best-found HD. Outer loop iterates with increased message length. The optimizations are a result of me having thought about the various cases for a long time, but you can turn them off if you're dubious. (I've run extensively both ways just to be sure).
ReplyDeleteI have not run GPUs or FPGAs. The hdlen code is how I do double-checks. The search code is a lot more complicated. If you're out at 100k bits you need a lot more speedup than even GPUs can provide, and it is unclear that FPGAs provide an advantage compared to better search algorithms, which I haven't had the time to talk about.
So please consider hdlen an intentionally simplistic double-check, and not a primary search algorithm.
Hello Phil,
ReplyDeleteCan the same techniques as described here be used to select a CRC16 for a very large amount of data, such as a header block stored in NVRAM? It seems some error types described (eg. burst errors) wouldn't be relevant in this case, the goal here is basic detection of silent corruption (bit rot) or corruption due to incomplete I/O (eg. power loss).
For example, using CRC16 polynomial 0xD175 on a 64KB (524K bits) long header, would it be safe to expect HD=2 but with worse error detection performance than selecting 0x8D95 (even though both will be HD=2 at that distance) since the data set is now longer than 32751 bits?
It all depends upon the polynomial. To answer this question you need to look at the Hamming Weights at a particular length for the polynomial you care about. You can find them up to, as it turns out, 512K bits here: https://users.ece.cmu.edu/~koopman/crc/crc16.html by clicking on the polynomial to see the detailed analysis.
ReplyDelete524288 0xd175 3932552 0
524288 0x8d95 1835172 366537431200
(Format: # dataword bits / polyonmial / HW @ 2 bit errros / HW @ 3 bit errors)
This indicates that 0x8d95 will have half the number of undetectable 2-bit errors as 0xd175, but many undetectable 3-bit errors.
In this case the "divisible-by-x+1" property of 0xd175 bites you by doubling the number of undetectable 2-bit errors at long dataword lengths.
Assuming 2-bit errors are more common than 3-bit errors (e.g., with random independent bit flip fault model), you're better off by a factor of 2 with 0x8d95.
That's why on the main summary table it is listed as best for HD=2 at unlimited length. (see https://users.ece.cmu.edu/~koopman/crc/index.html)
Hello Phil,
ReplyDeletelets say I exceed the performance of a polynomial by e.g. protecting 5010 data bit using a polynomial that only supports 5000 bit for a certain HD. Is there a way to analytically calculate the chances that an error is not detected? (under the assumption of a low, constant, random, independent BER)
I was thinking about using a CRC width that (even when choosing the optimal polynomial) does no exactly meet my data size - which would be ok as long as the error chance is below a certain limit.
All things being equal you should find a polynomial that is good at that longer length, because for "good" polynomials typically get good at long lengths in exchange for falling off a cliff (HD=2) at even one bit longer.
ReplyDeleteIf you want to know the performance click on the link to Hamming Weights for the polynomial of interest and you can compute the exact performance under that fault model. But if you just want a ballpark estimate, you're at ballpark 1/(2**k) for a k-bit CRC value for anything beyond the HD.
BTW, I think it is likely that you can get the original HD in this situation for bit errors that cluster close together, so in some cases maybe it is better. But I haven't had time to firm that up to provide concrete guidance.
DeleteHello Mr. Koopman,
ReplyDeletedo you know of any heuristic method to predict the performance (i.e. max. payload size) of a given polynomial at a given HD of 5 and above? Such a method don't need to be very precise. Even a rough estimate would be EXTREMELY helpful when searching for optimal polynomials.
As far as know there is no heuristic method, just brute force search.
ReplyDeleteBut I've already done the searching for you here:
https://users.ece.cmu.edu/~koopman/crc/hd5.html
or more generally here:
https://users.ece.cmu.edu/~koopman/crc/index.html
Of course I have seen your great work there. Thanks for that! I also have seen your HDLen code.
ReplyDeleteI tried to write similar code for GPUs. But I failed because the performance between polynomials varies a lot in an arbitrary way, which kills the performance on SIMD architectures due to thread divergence. One way to solve that would have been to roughly sort the polynomials by expected performance so the actual brute-force computation is more efficient.
Seems I am stuck if there isn't such a heuristic.
Is HDLen the only publicly available code for performance computation? Have you ever seen alternative/primitive implementations that is able to compute an entire HD for a given polynomial without recursion, without nested loops and without multiple different conditional exit branches? Such a code, even when less efficient on GPUs, could be a game changer on a GPU.
The fast algorithms tend to require lots of memory for various reasons to speed things up beyond the HDLen code.
ReplyDeleteIf you want GPU friendly code (which I have never tried) you don't have to have recursion -- it is just more convenient to write it that way. A set of nested loops for a particular HD will work the same. (You'll need different loop source code for each HD, but there aren't that many HDs you care about.) Then batch up a set of polynomials and run all combinations of bits across all of them.
There are some heuristics for faster search campaigns in section 4.1 of this paper:
https://users.ece.cmu.edu/~koopman/networks/dsn02/dsn02_koopman.pdf
Those "fast algorithms" are closed source? How much is "a lot of memory"?
DeleteThis "outrolling" of recursive code is something I have already tried for HD=5. It works and actually gives some significant speed-up of >10% compared to an implementation that uses pseudo-recursions on a manually managed stack.
Still this is small compared to the slow-down caused by the huge and (seemingly) arbitrary payload differences between polynomials (resulting in huge loop-count differences, leading to huge thread divergence). That effect results in a slowdown in the dimension of 2000% which is a total show-stopper.
Since there seem to be no heuristics, the only workaround (I can think of) would be a single-loop solution that is able to compute payloads for HDs > 4. I would have ideas how to exploit such a single-loop implementation to maximize GPU utilization.
But looking at your HDLen code, e.g. for HD=5 a minimum of two nested loops is required. Using the optimization option even three loops. The accumulator manipulations inside those loops are similar to each other but the exit conditions differ a lot. I can't think of a way to solve this using only one uniform loop without big divergent branches.
I'm looking for a CRC that is tailored to I2C and a few Flash specific issues. Namely that all bits are one after an error. For I2C this is the case when the transmitter detects an error and stops sending or for Flash this is the case when the write process has been aborted at some point. Flash is usually cleared to one. Are there implementations where this arbitrary long but special error is always detected? The length is known for these two examples.
ReplyDeleteThere is a special class of codes called "erasure" codes that might do a little better, but I don't have handy info on them.
DeleteYou might try adding an extra data bit at the end of your data stream to ensure the CRC value itself can never be all ones. (that bit should be either odd or even parity depending on the CRC.)
Thanks, i hoped that there is a more elegant approach, but adding an extra non 0xFF Byte at the end will work.
Delete